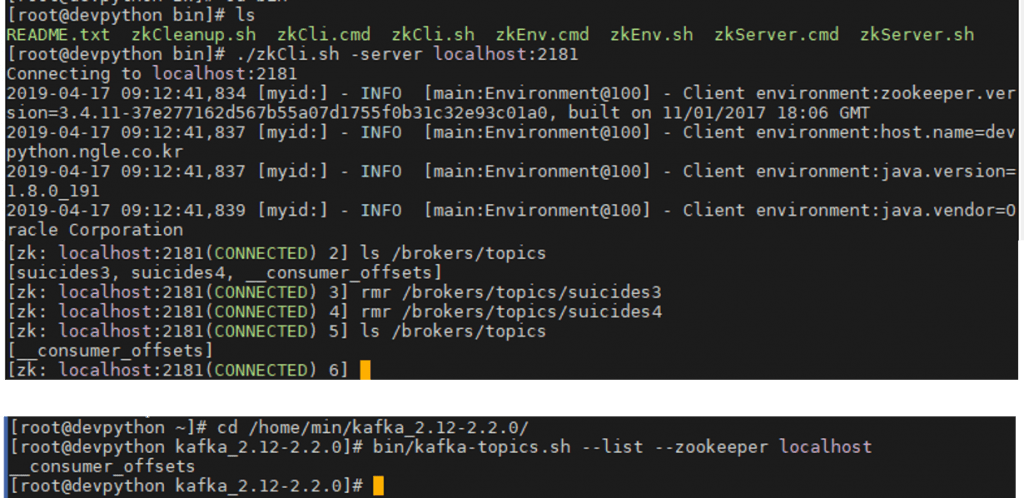
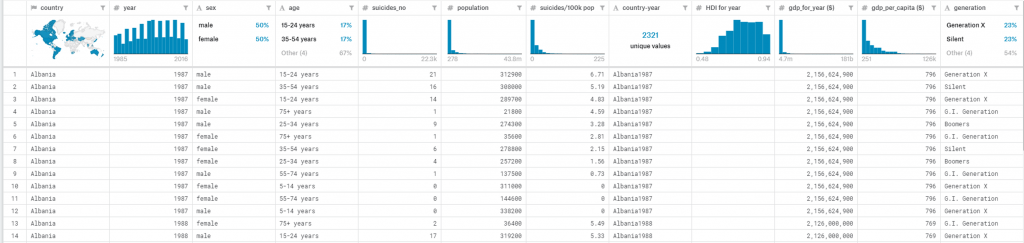
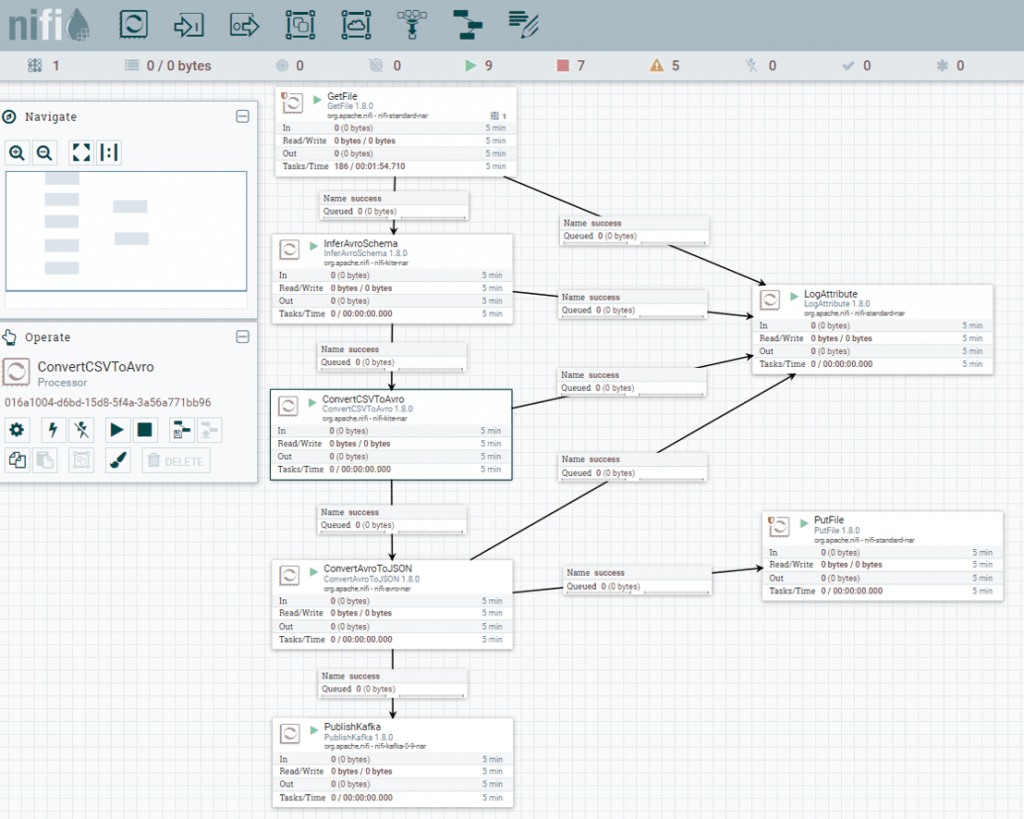
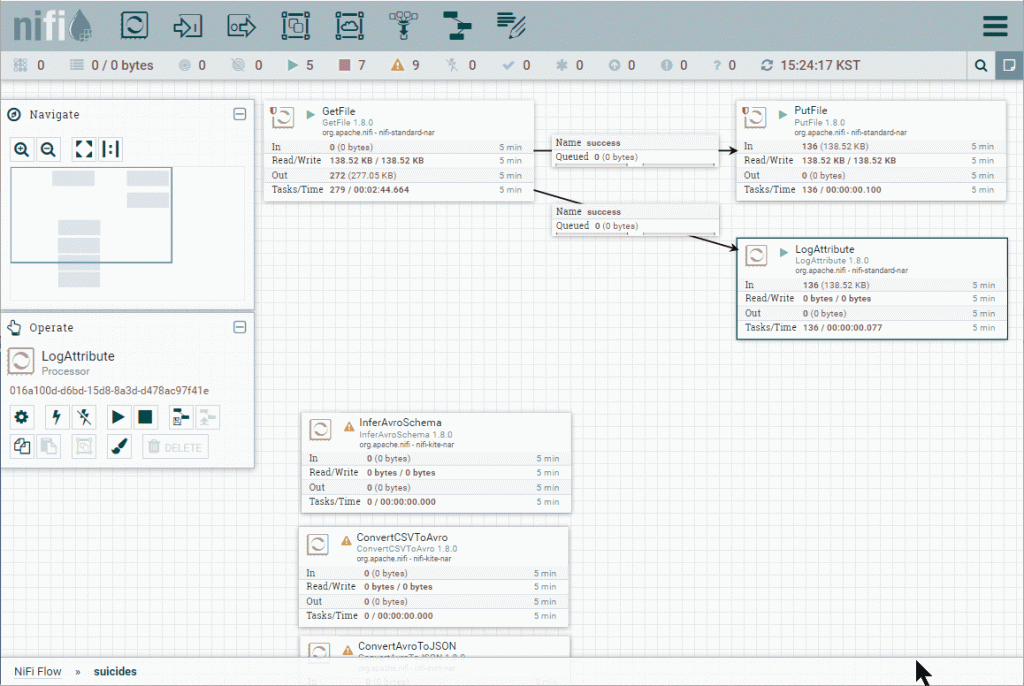
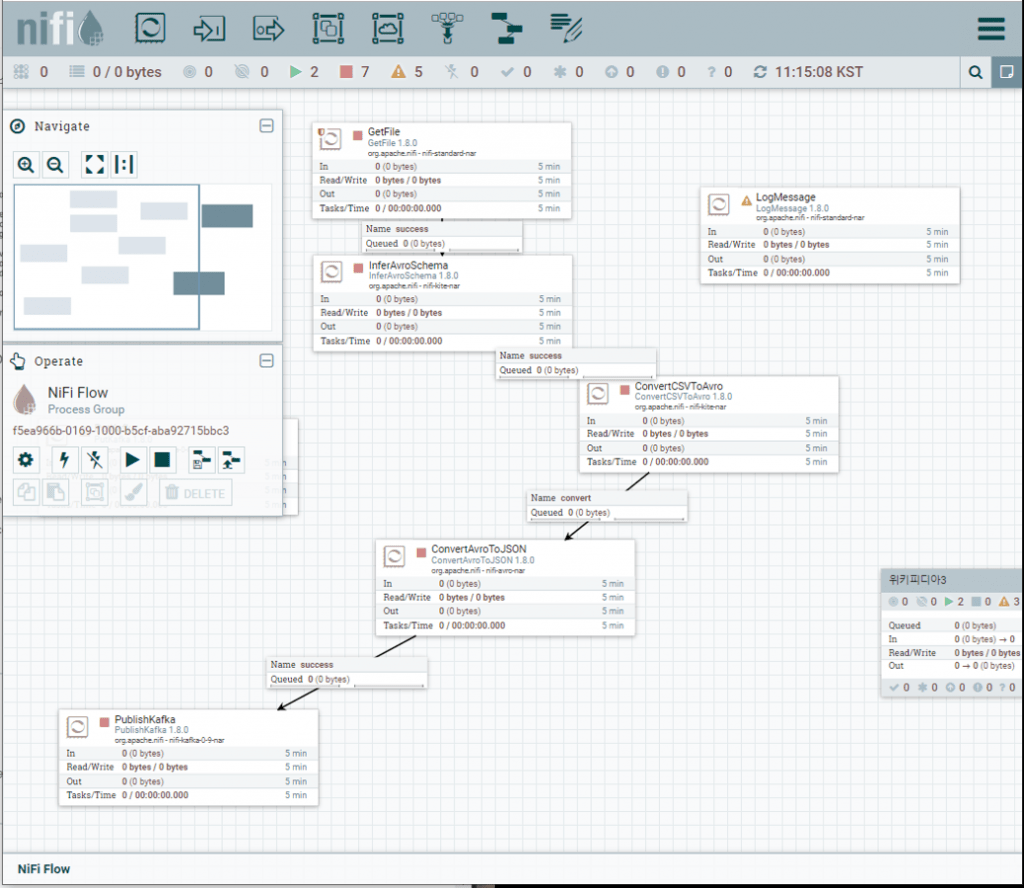
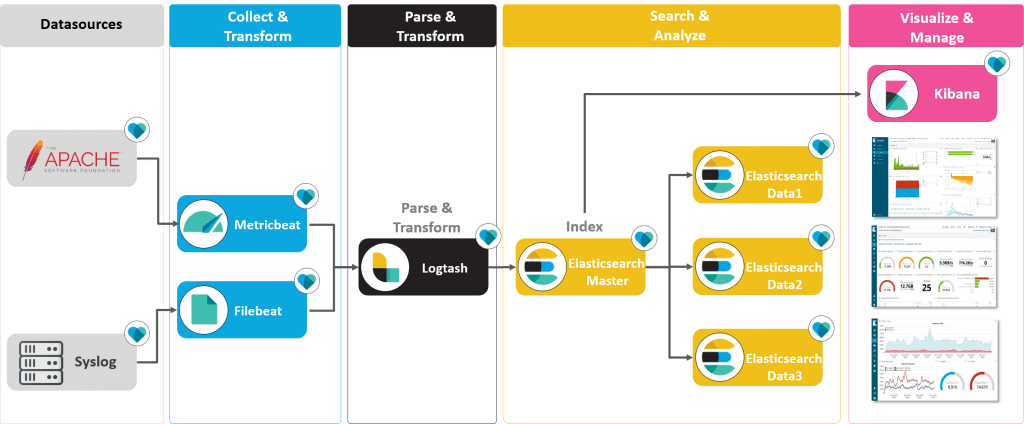
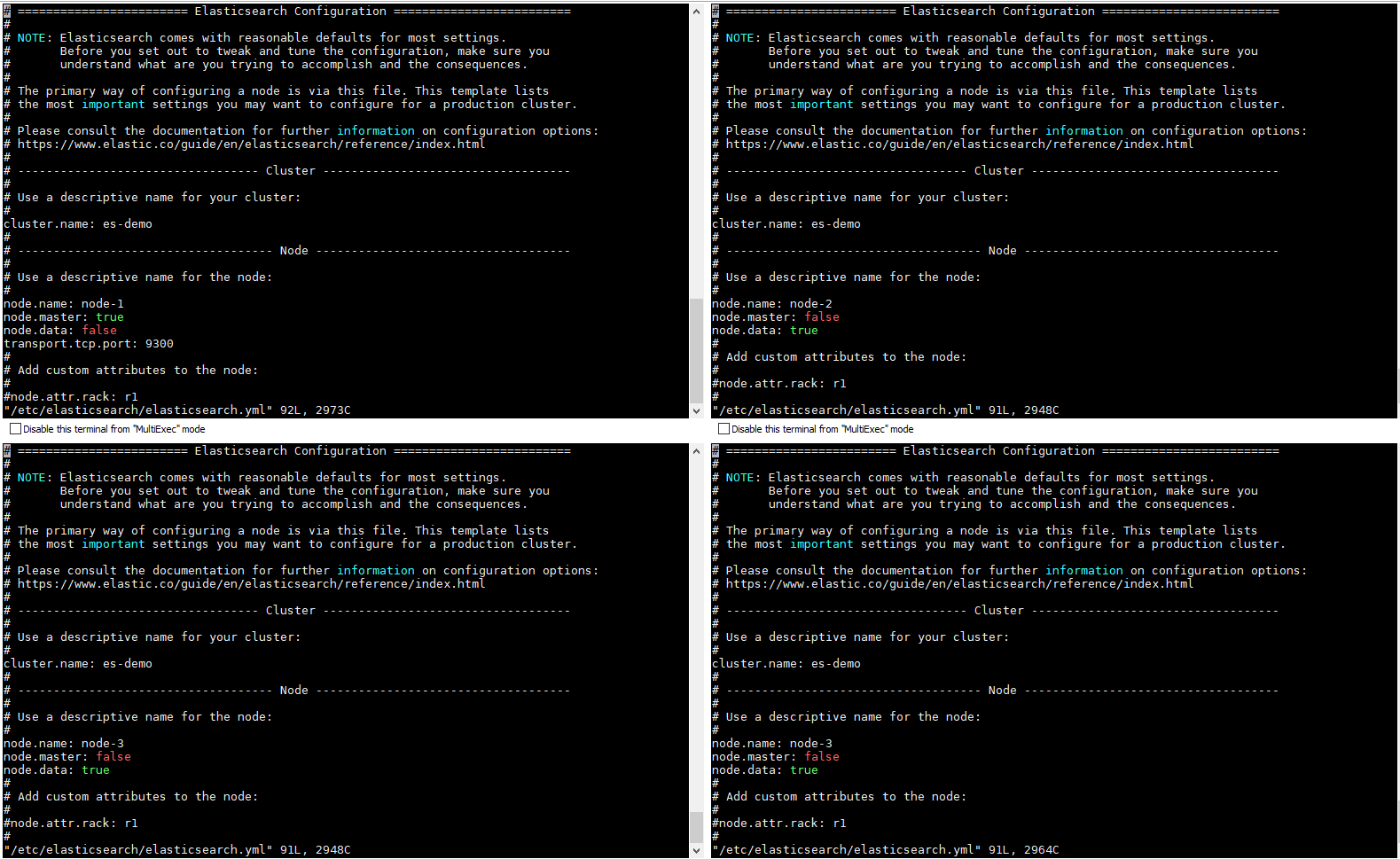
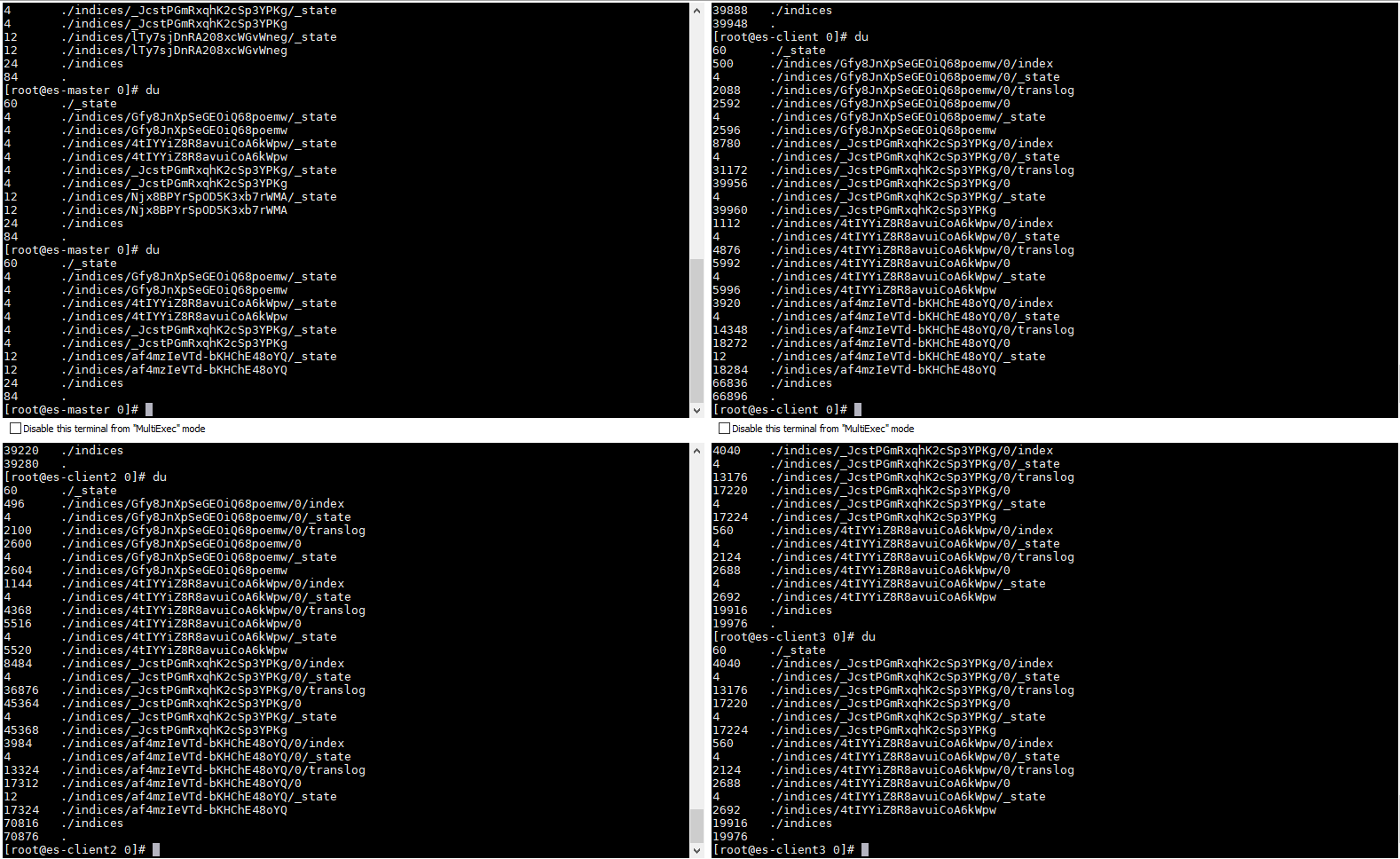
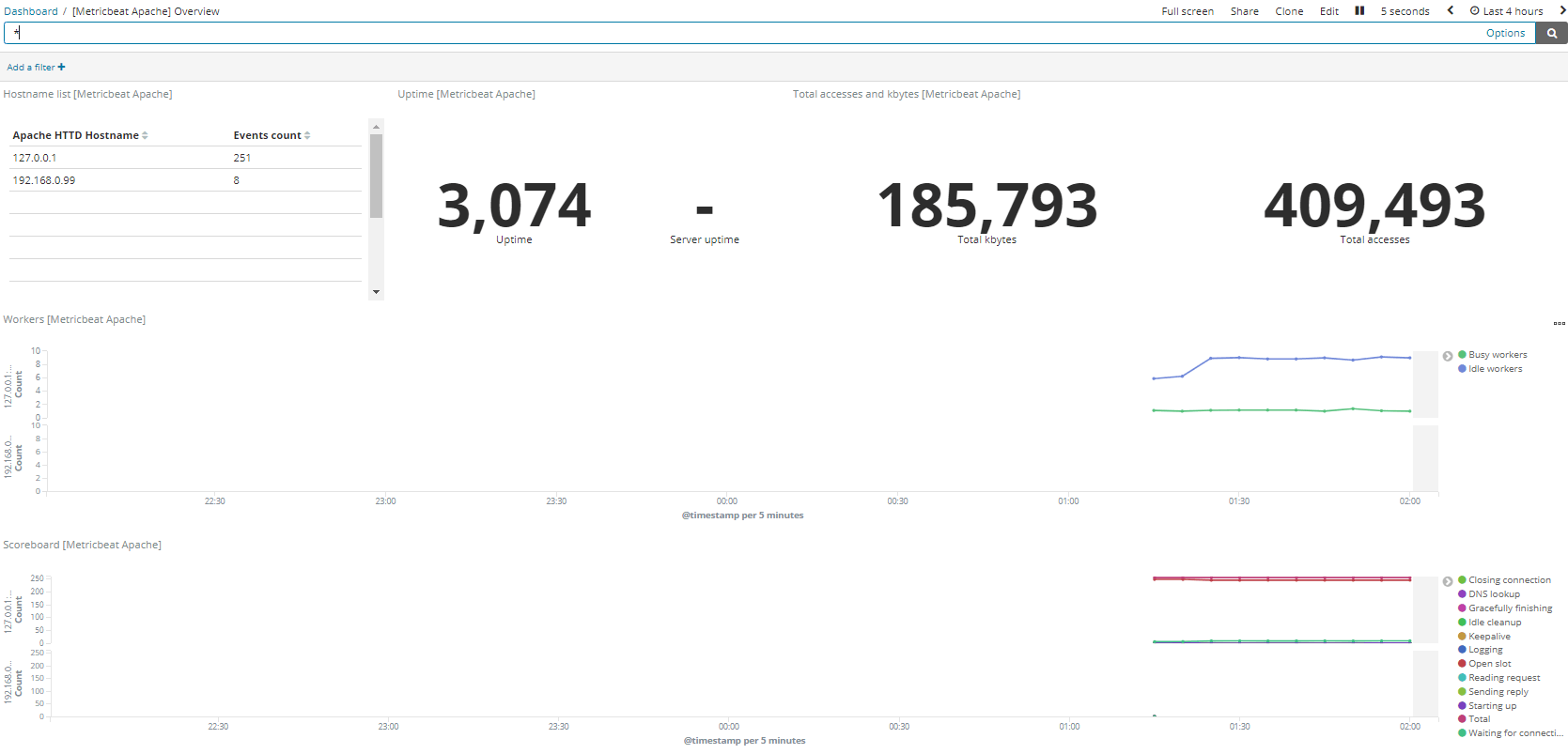
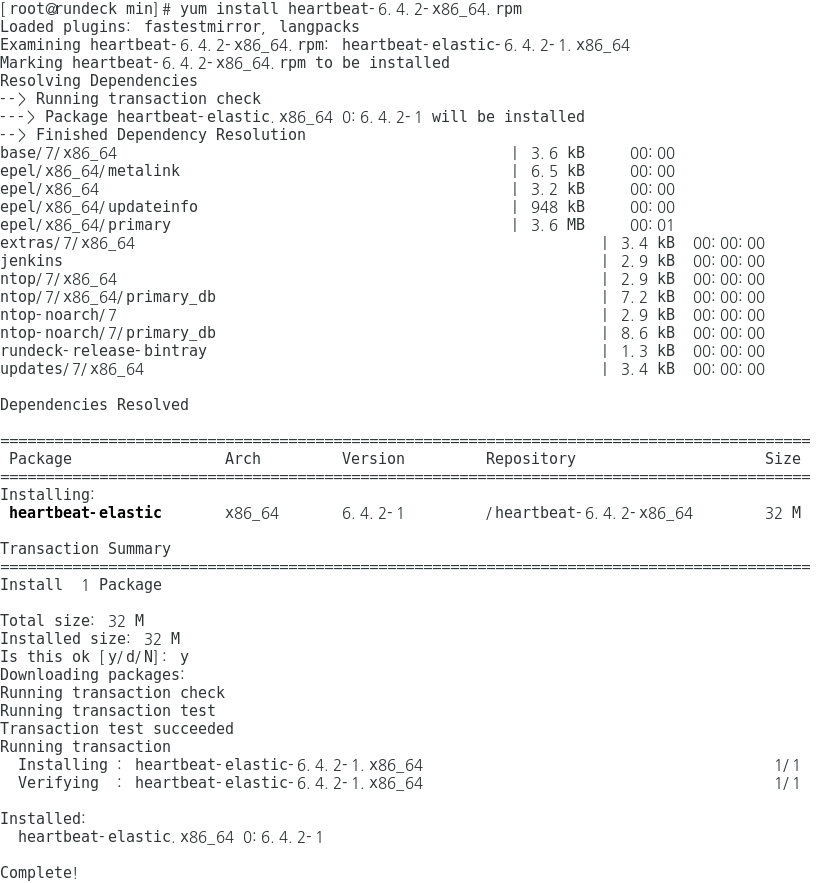
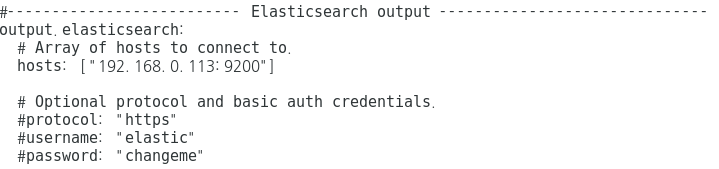
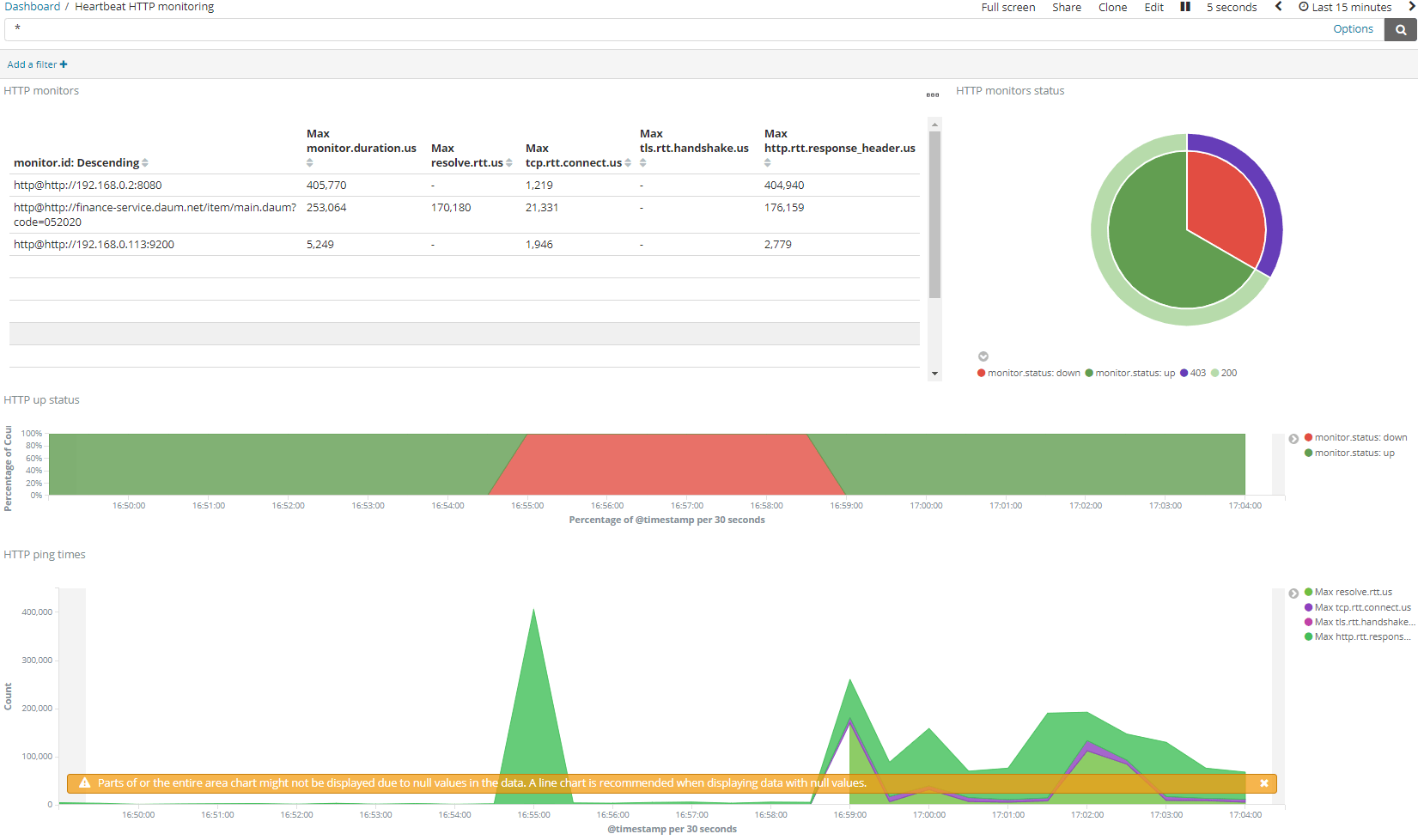
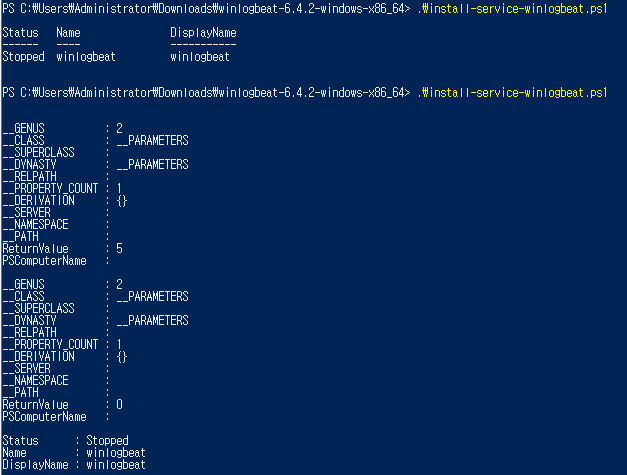
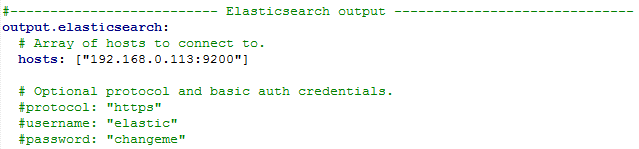
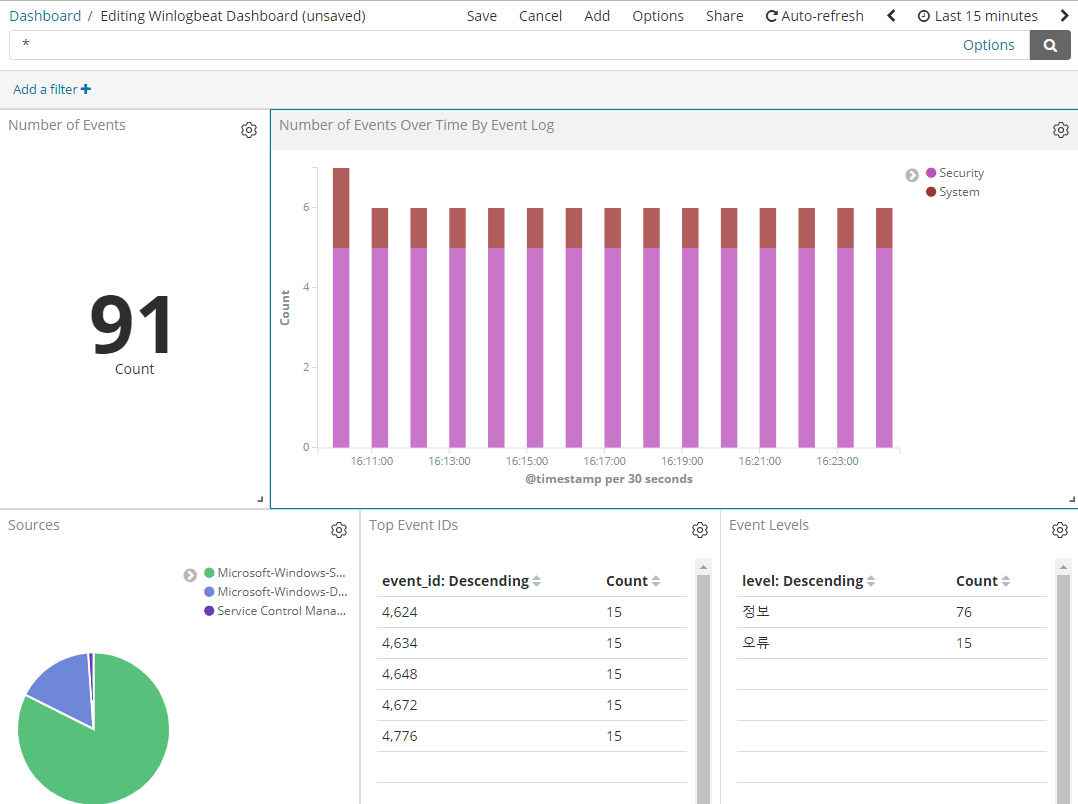
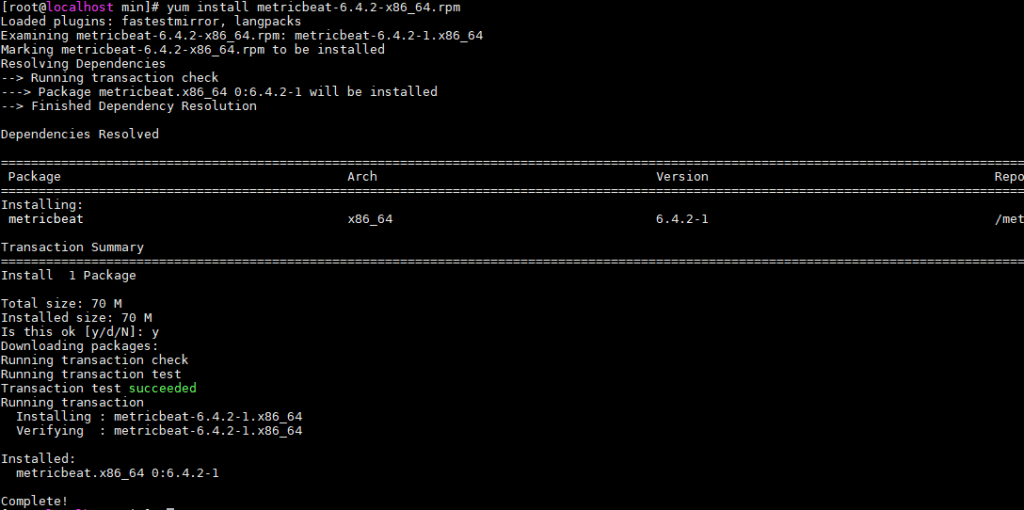
### Create topic
kafka/bin/kafka-topics.sh –create –zookeeper 192.168.0.145:2181,192.168.0.175:2181,192.168.0.175:2181 –partitions 3 –replication-factor 3 –topic suicides
### List topic
kafka/bin/kafka-topics.sh –list –zookeeper 192.168.0.145:2181,192.168.0.175:2181,192.168.0.175:2181
### descirbe topic
[root@kafka1 min]# kafka/bin/kafka-topics.sh –describe –zookeeper 192.168.0.145:2181,192.168.0.175:2181,192.168.0.175:2181
Topic:suicides PartitionCount:3 ReplicationFactor:3 Configs:
Topic: suicides Partition: 0 Leader: 3 Replicas: 3,1,2 Isr: 3,1,2
Topic: suicides Partition: 1 Leader: 1 Replicas: 1,2,3 Isr: 1,2,3
Topic: suicides Partition: 2 Leader: 2 Replicas: 2,3,1 Isr: 2,3,1