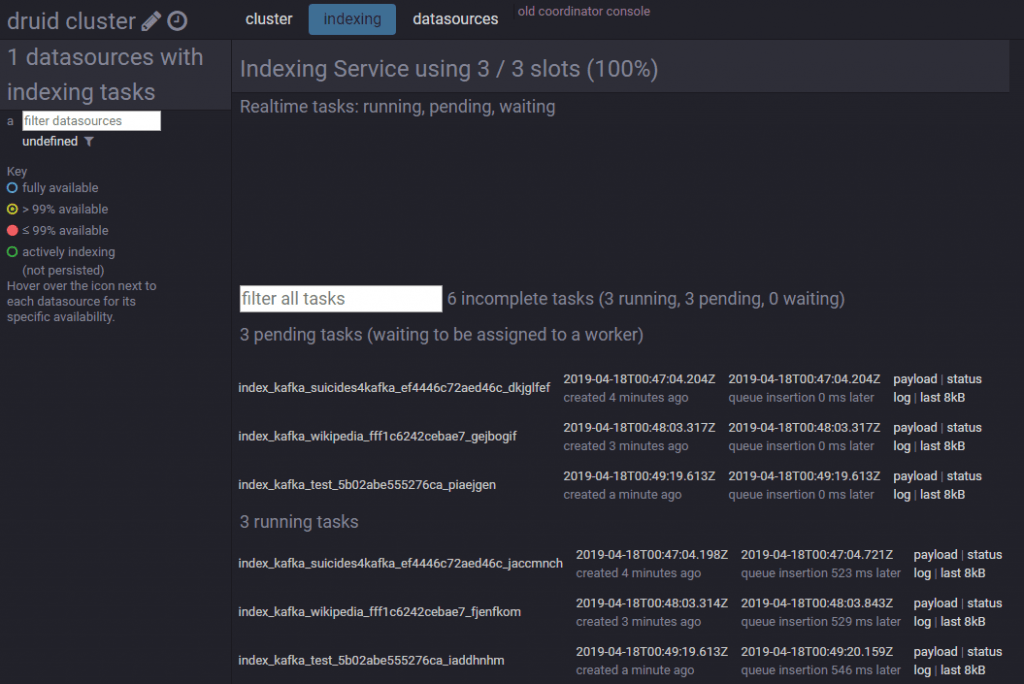
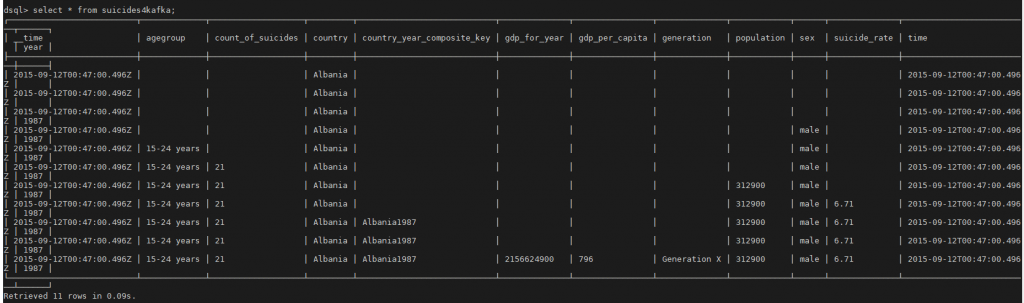
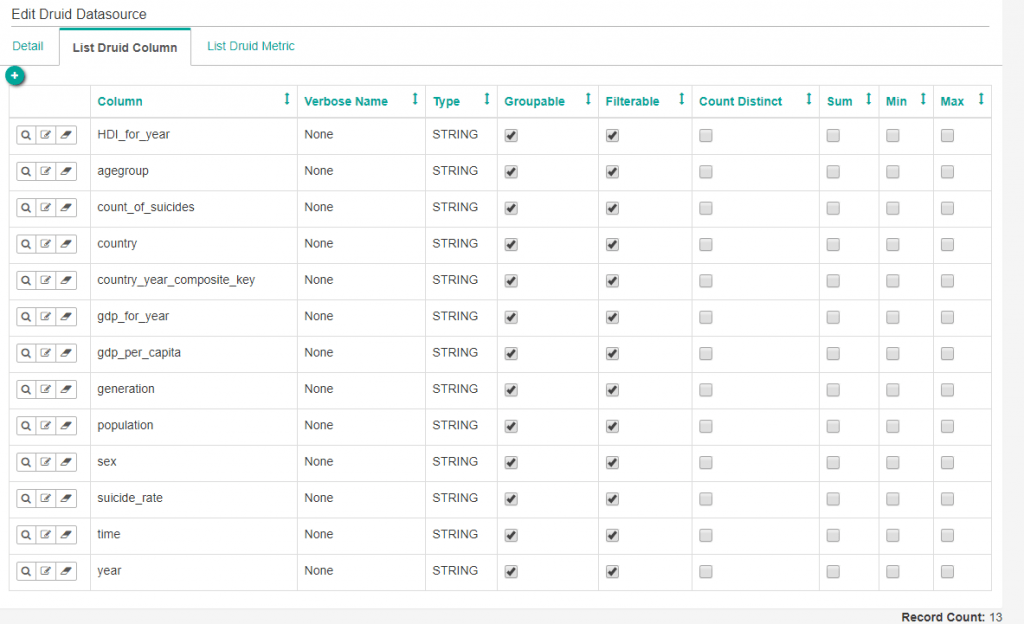
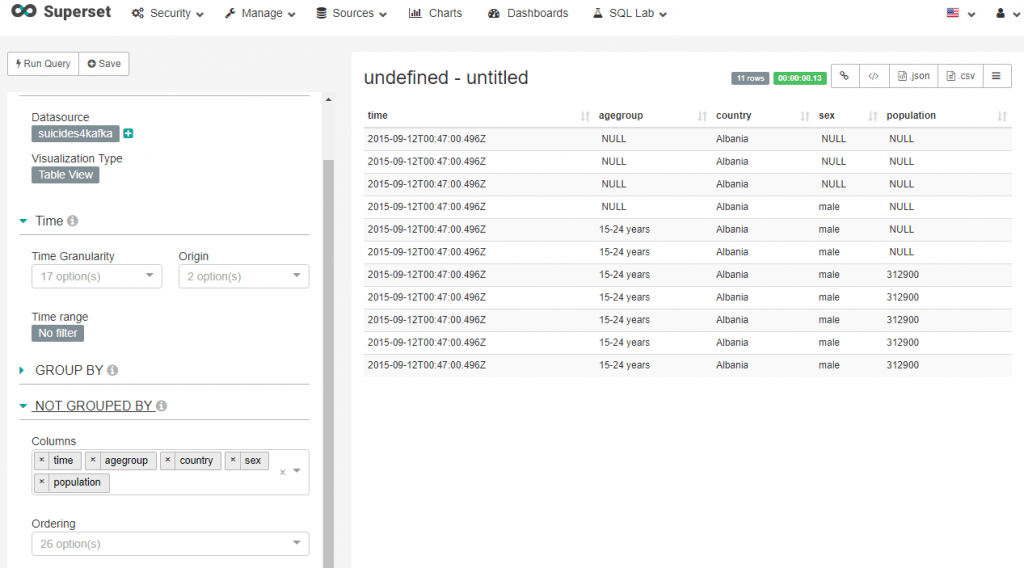
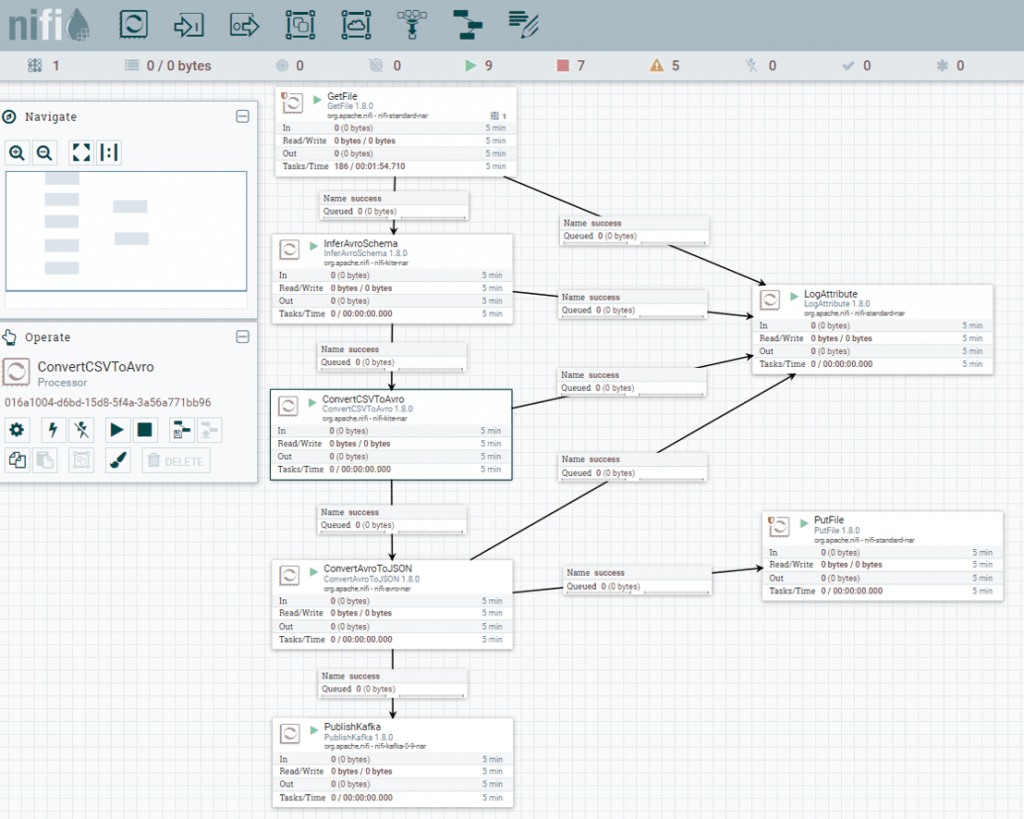
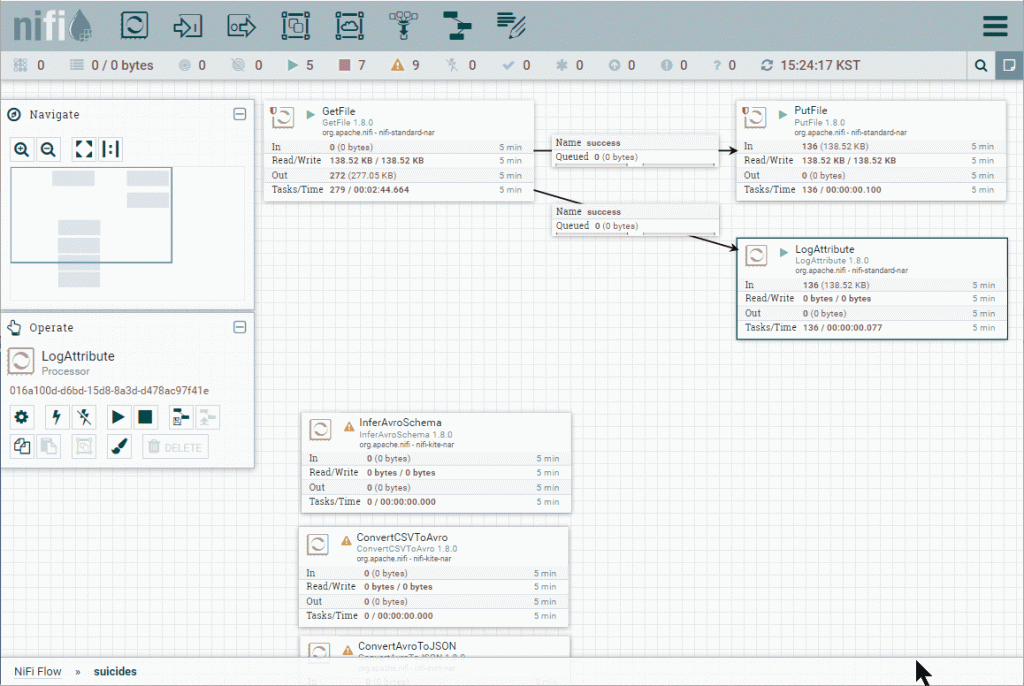
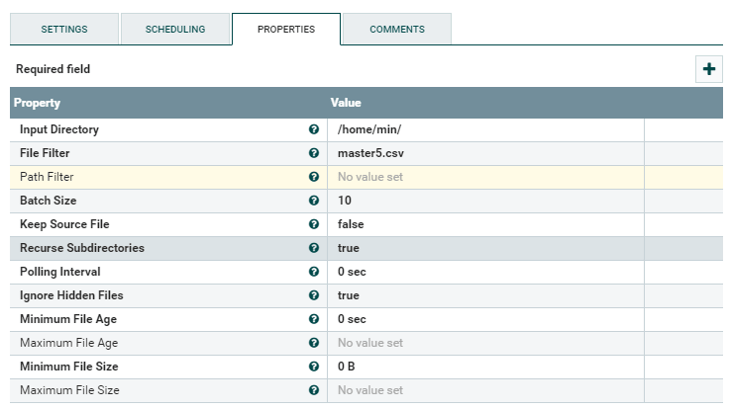
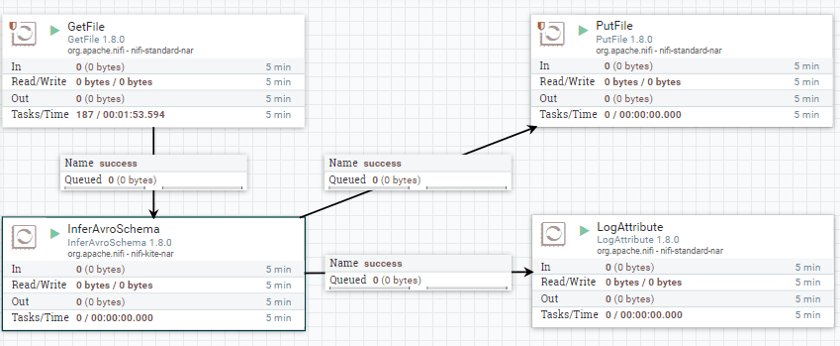
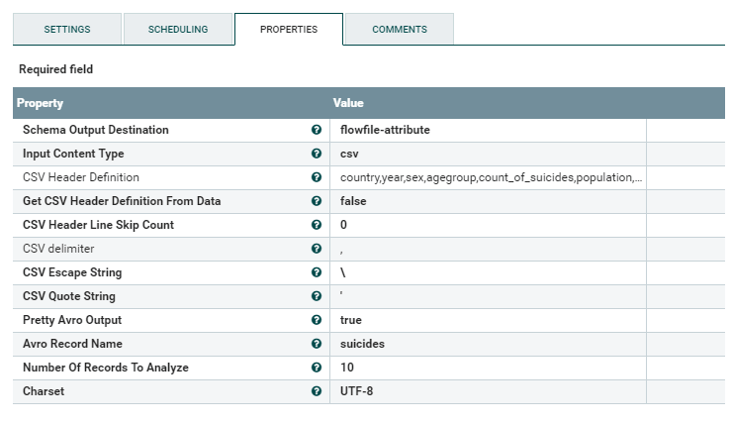
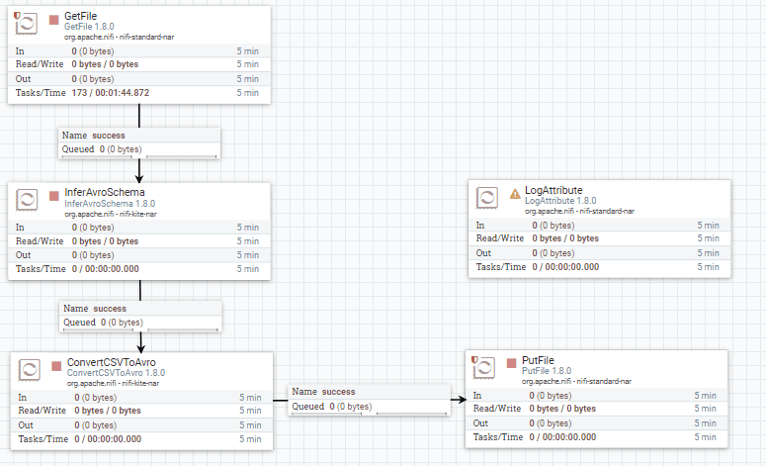
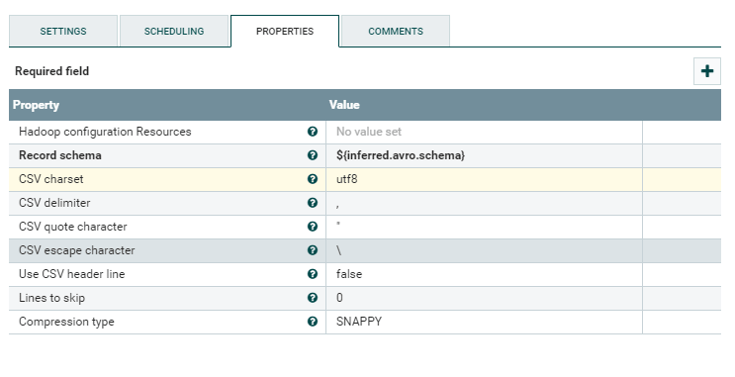
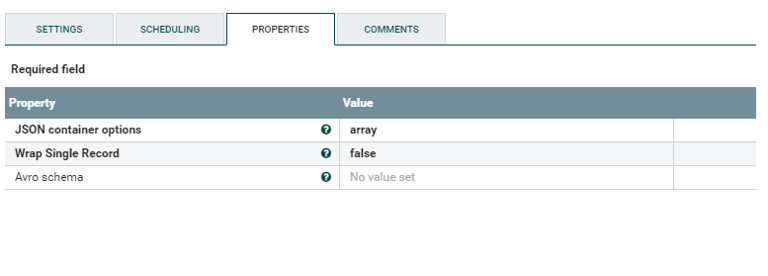
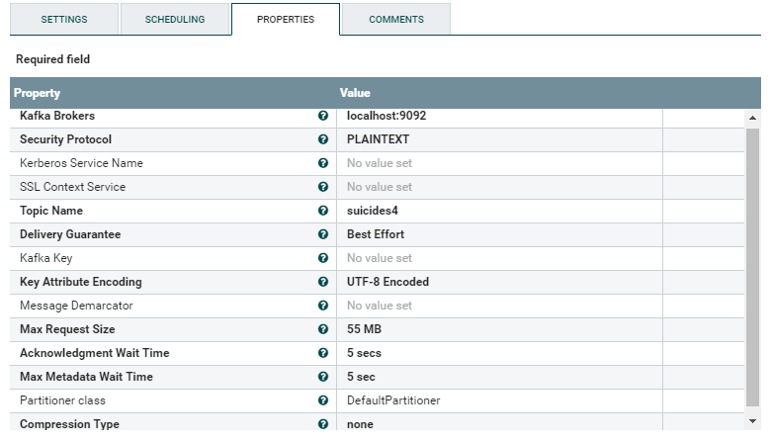
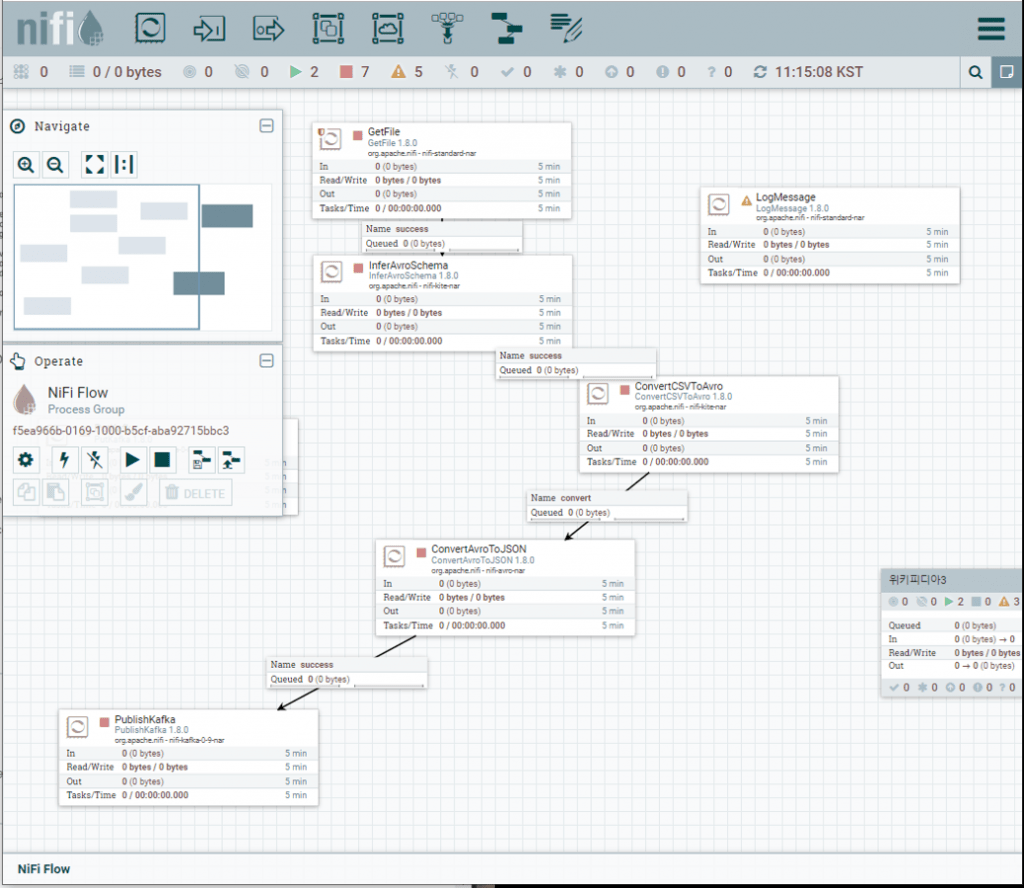
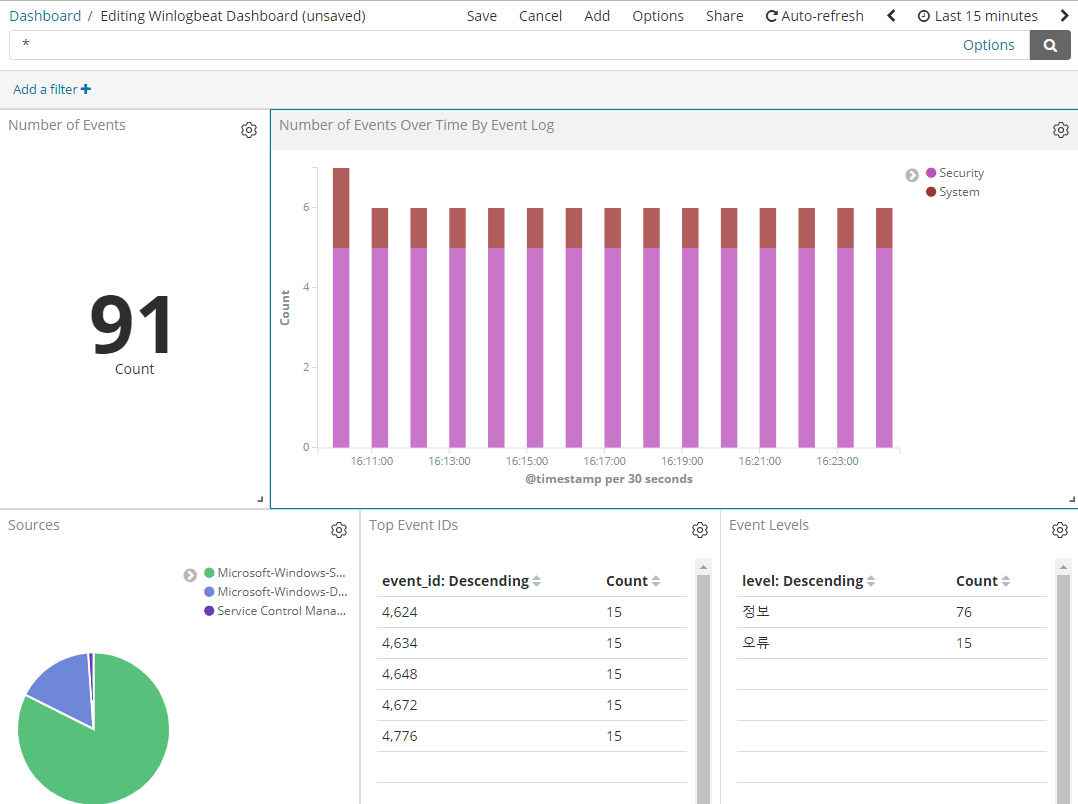
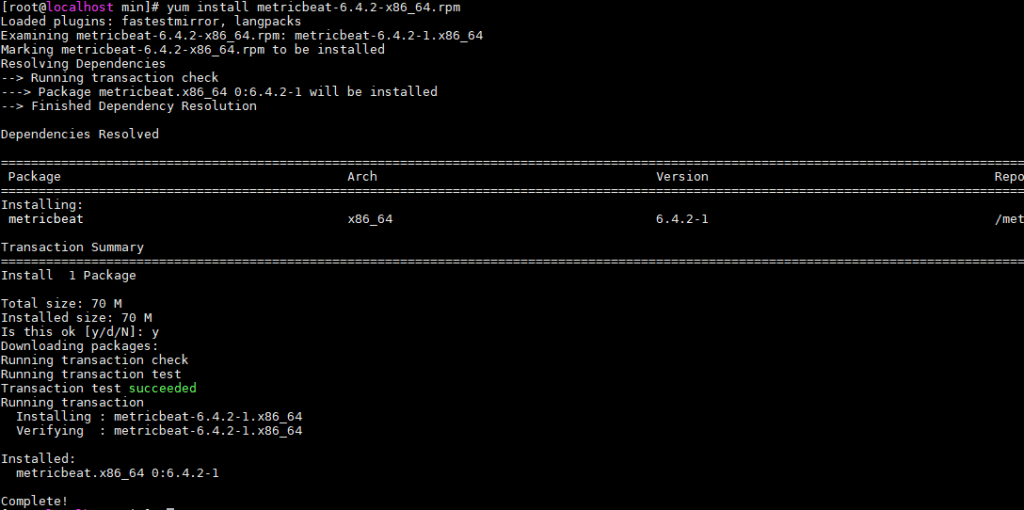
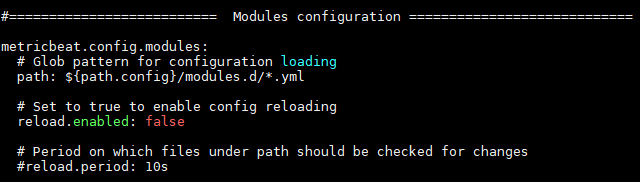
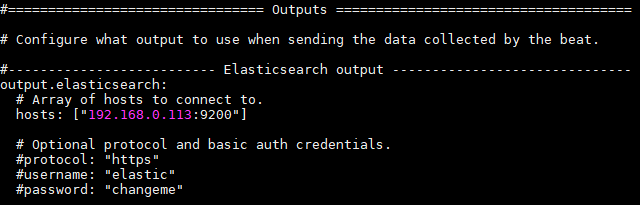
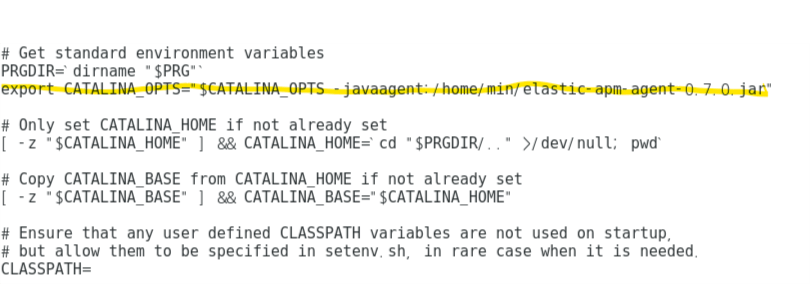
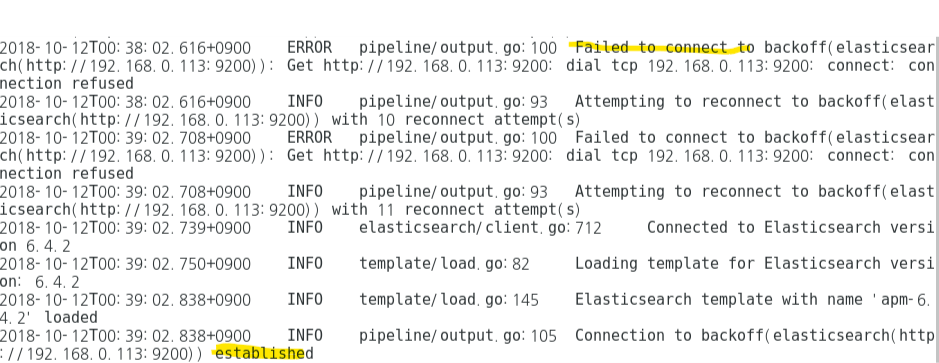
vi sucides4-kafka-supervisor.json
{
“type”: “kafka”,
“dataSchema”: {
“dataSource”: “suicides4”,
“parser”: {
“type”: “string”,
“parseSpec”: {
“format”: “json”,
“timestampSpec”: {
“column”: “time”,
“format”: “auto”
},
“dimensionsSpec”: {
“timestampSpec”: {
“column”: “time”,
“format”: “auto”
},
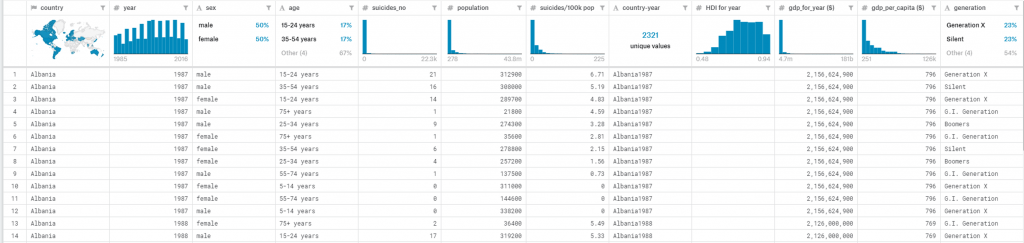
“dimensions”: [“time”,”country”,”year”,”sex”,”agegroup”,”count_of_suicides”,“population”,
“suicide_rate”,”country_year_composite_key”,”HDI_for_year”,”gdp_for_year”,”gdp_per_capita”,”generation”]
}
}
},
“metricsSpec” : [],
“granularitySpec”: {
“type”: “uniform”,
“segmentGranularity”: “DAY”,
“queryGranularity”: “NONE”,
“rollup”: false
}
},
“tuningConfig”: {
“type”: “kafka”,
“reportParseExceptions”: false
},
“ioConfig”: {
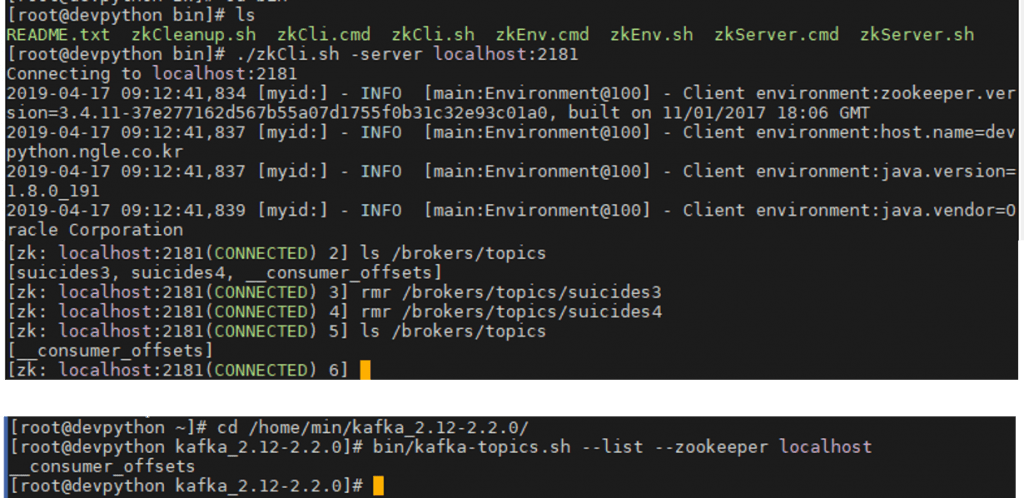
“topic”: “suicides4”,
“replicas”: 2,
“taskDuration”: “PT10M”,
“completionTimeout”: “PT20M”,
“consumerProperties”: {
“bootstrap.servers”: “localhost:9092”
}
}
}